
IBM leadership with Adolf Hitler
In 1939, under the direction of its president, Thomas Watson, IBM released specialized alphabetizing machines.
These machines along with other IBM products played a pivotal role in organizing the deportation of Polish Jews for Nazi Germany.
The IBM leadership didn’t just passively supply; they actively marketed their technology directly to Hitler and his top officials.
Just a few years prior, IBM’s CEO, Tom Watson Sr., had even been honored with a “Service to the Reich” medal.
The company implemented a punch card system to track the method of execution and the ethnicity of each victim.
And to ensure these machines ran efficiently, IBM staff were often present on-site at concentration camps for operation and maintenance.
IBM thrived financially and technologically, but at what cost to humanity?

IBM concentration camp punch-card - Source
We are all aware of the horrors of the holocaust and can agree IBM’s involvement is an egregious example of focusing on technology without care to its impact on society.
Nowadays we are fortunate enough to be in, for the most part, more peaceful times.
However the same ethical questions still arise with development of new technology everyday that changes the way we interact with the world.
The impact of newer tech is often less obvious.
It is clear that directly cooperating with genocidal regimes like the case of IBM or skirting public safety regulations like Theranos with their “one drop of blood” medical diagnostic machines are both extremely unethical decisions.
Compare those examples to the common modern case of a recommendation algorithm running on a computer in a distant server farm that chooses what content people see on a website or app.
At face value it seems much more benign right?
Algorithms must be more objective because they are based on data, and in the case of machine learning algorithms, lots and lots of data at that.
It might seem that way at first until you discover that your video recommendation system is curating playlists of prepubescent partially clothed children to drive engagement of pedophiles on your platform.
This was a very real problem caused by YouTube for the families who had uploaded their innocent home videos of their kids simply enjoying a pool day.
The objectives of the algorithm behind Youtube’s pedophilia curation was actually quite similar to the that of IBM and Theranos.
Similar to IBM’s CEO Tom Watson and Theranos CEO Elizabeth Holmes, the algorithm strived to optimize it’s performance metrics by any means necessary.
When the algorithm received positive feedback by seeing the time spent by a user extremely interested in videos of partially clothed children increase, it was reinforced to serve them more of that content.
When Tom Watson saw IBM profits soar when selling services to Nazi Germany, he was positively reinforced to develop more efficient systems to support genocide.
When Elizabeth Holmes saw herself becoming more and more famous by deceiving patients, employees, and investors, she was positively reinforced to keep the act going.
Each of these actors was caught in a feedback loop that rewarded them for helping the depraved at the expense of the innocent.
Each actor lacked a moral compass to point them in a better direction for the good of society.
Lastly, each actor did not act alone and had supporting actors that were privy to was going on.
They too bear responsibility as they were complicit in the ethical violations of their company.
A major difference to consider between these actors is that even though algorithms are biased like people, they are not actually people (yet).
However, they still inherit the biases of the people that created and trained them.
Types of biases
Let’s define a few different types of biases inherited from people to machine learning algorithms.

Historical bias
People, processes, and society are inherently biased stemming from the past which effects all datasets.
Example race bias:
Black people have historically been victim to racism by white people and this is reflected in data used by algorithms.
The COMPAS algorithm that determines sentencing and bail in the US showed obvious racial bias by disproportionately labeling black Americans as higher risk to re-offend than white Americans by ~20% despite the results showing the predictions should be much closer.
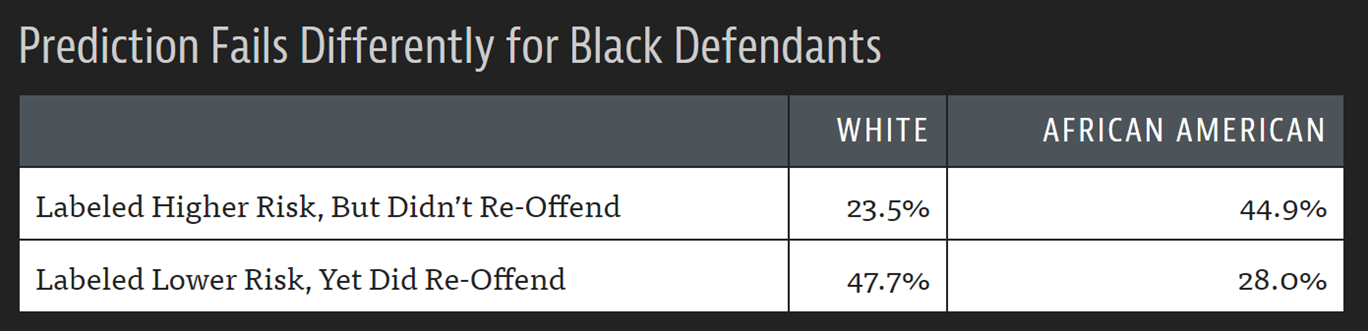
Measurement bias
When we measure the wrong thing or measure it in the wrong way, models make mistakes.
Example:
Predictive models trained on electronic health records determined which factors such as “colonoscopy” and “accidental injury” are highly correlated to being diagnosed with a stroke.
The real prediction here is that people who are more likely to go to doctors at all are more likely get diagnosed with a stroke because they show up more often in the first place.
Representation bias
This one was confusing to me as it seems awfully similar to historical bias.
The idea is that models amplifies the existing bias in the dataset they are trained on.
Example:
In society there are some occupations that employ more women than men.
For example, there are more women who are nurses and there are more men who are pastors.
Occupation prediction models not only demonstrated the existing gender discrepancy across occupations but also over amplified the numbers.
Women were more likely to be nurses while men more likely to be rappers both at a significantly higher margin than was actually true in the training data.
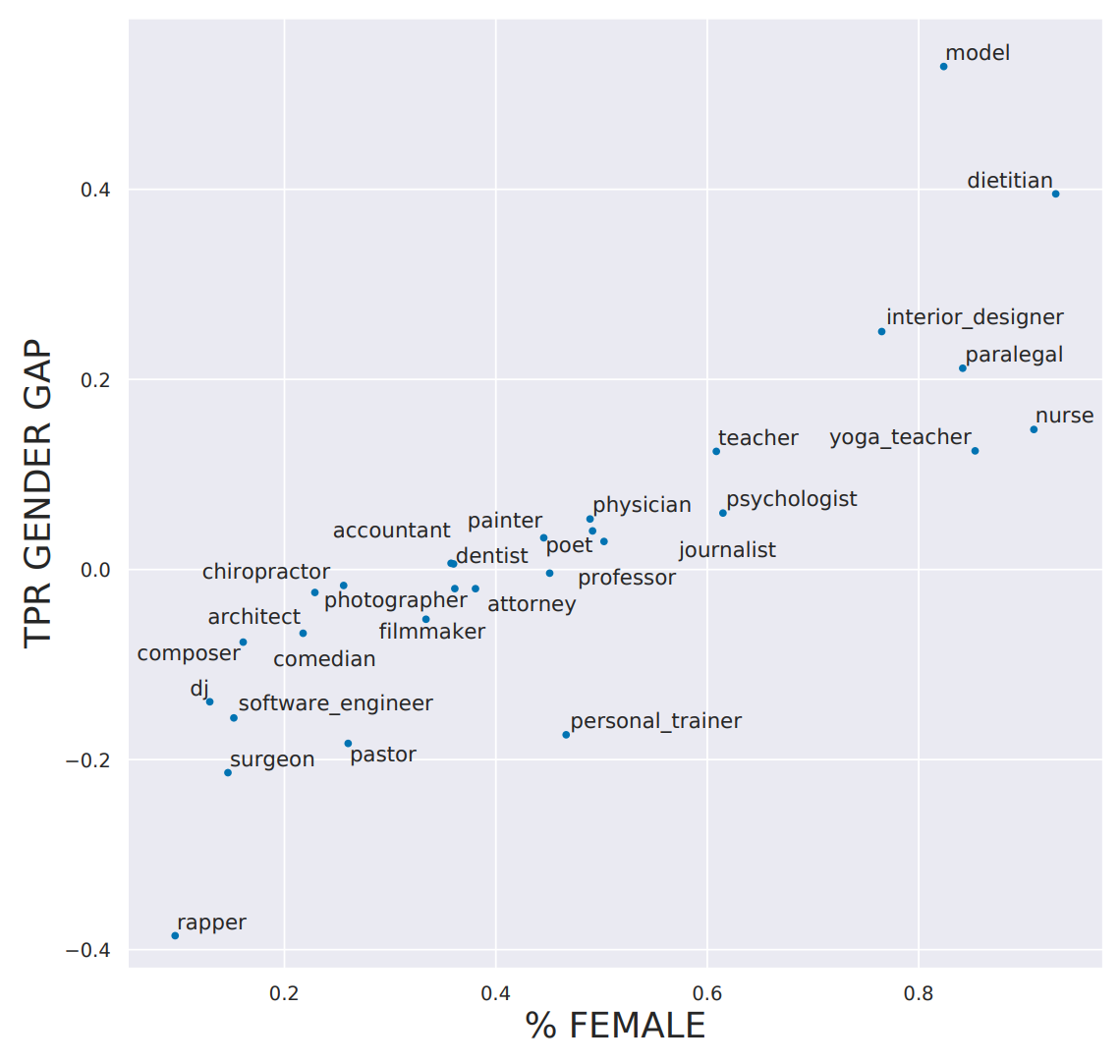
That example seems similar to the COMPAS algorithm as both seem to stem from historical bias.
One exhibits gender bias and the other racial.
Maybe the difference lies in how large the amplification of bias between predictions and the training data is.
Responsibility of data engineers
The consideration of ethics maybe isn’t for everyone.
It is more suited to people with a growth mindset who want to better themselves along with the world around them.
People who spent the time to get through school and work their way into the data science field are definitely capable of logically analyzing complex systems.
It is a matter of devoting some of their brain power they spent years building to think about how the model they are training can better serve people and animals outside of their company rather than just the ones within.
There are no 100% correct answers when it comes to handling biases ethically.
However, there is value in weighing which approaches are better and which are worse.
Although algorithms are not people, hopefully you are convinced that they do inherit the biases of people.
In comparison to traditional hardware tech, algorithms are:
- cheap to develop
- more likely to be implemented without an appeals process
- capable of scaling quickly
This makes them more volatile and prone to feedback loops that can be highly detrimental.
What are some counter measures data engineers can take?
- Make algorithms more transparent and able to be visualized by non-technical people
- Use more gradual deployment processes with more (diverse) human verification at steps along the way
- Think about what bias is in training data and how to mitigate it such as sometimes choosing to omit some biased factors such as ‘gender’
- Ask questions like “How might future generations be affected by this project?” or “Which option will produce the most good and do the least harm?”
Thanks for reading all the way through!
If you are curious about reading on about other cases of algorithms gone wrong these were interesting reads:
Discrimination in Online Ad Delivery by Latanya Sweeney
What happens when an algorithm cuts your health care